Over the last few weeks we have noticed that many of the nodes in the SLACVX cluster now seem to typically only deliver about 50% of the expected CPU cycles, and spend the other 50% of the time idle, even when they are running what we have traditionally thought of as CPU intensive tasks. It is unclear how long this situation has been going on, certainly in the early days of the SLACVX cluster it was not so, and there are some anecdotal hints that things have gotten worse recently, but the plot of cluster CPU usage for the last years, as well as MC performance over the last year, suggest that the problem is of a longstanding nature.
I have run a number of tests of CPU speed, IO speed and network bandwidth over the last few weeks, the results of which are summarized below. They do not point to any single smoking gun, although they suggest a number of areas for further study.
We have traditionally thought of our MC farm as being CPU intensive, however we now calculate the each MC job causes about 0.3 MB/sec of IO, and since can run 20 jobs simultaneously the comes to 6MB/sec, which certainly taxes both the network and IO speed of SLACAX. We should investigate writing the intermediate output of the MC jobs to disk on the satellite nodes (as we used to), rather than writing it to disk on SLACAX, or alternatively investigate running MC+recon as one job instead of two.
Even after looking at all of these it may be that the real bottleneck is SLACAX itself, in which case no short-term fix may be possible to solve the problem.
The test job was run at approximately five minute intervals over the last 9 days. Each time the jobs ran it would be assigned (approximately) randomly to one of the satellite nodes or to SLACAX itself. Each job timed a number of activities:
Each time teh tets jobs ran it also recorded the number of bactch jobs running on each node of the cluster, categorized as:
The results of these tests are summarized below. Due to a bug in the test program the start and end time of each timing test was only recorded to the nearest second, resulting in some spikiness to the IO rate distributions, which must be integrated out by eye. All plots were made using Java Analysis Studio.
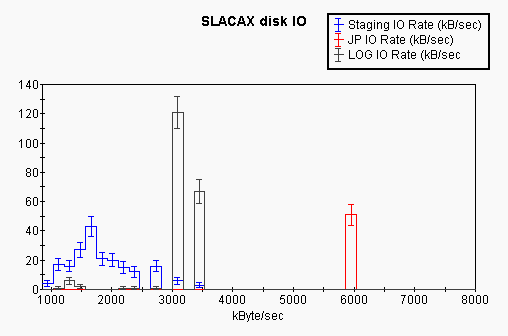
The first plot compares the IO rate when running on SLACAX itself for access to the three different types of disk:
It can be seen that the IO rate for the JP_user0 disk is about 6MB/sec, for the LOG disk it is typically 3-3.5 MB/sec while the staging disk peaks at the same 3-3.5MB/sec but is typically much lower, presumably due to load (see below).
Reading the same three disks from the satellite nodes resulted in very different results:
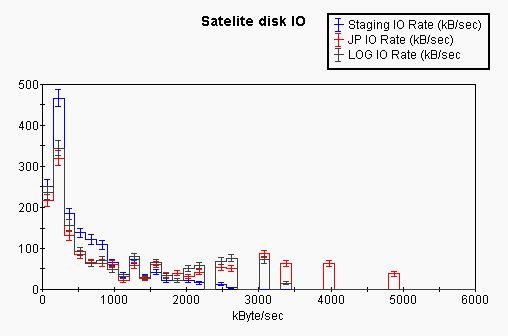
It can be seen that IO rate to all disks is typically below 0.5MB/sec, with all three disks showing a wide distribution in rates. The peak performance for each disk approximates the rate seen on SLACAX.
It can be instrucive to see the variation of the IO speed as a function of time sice this gives some handle on how load effects IO rate. This is shown for both SLACAX and satellite nodes below, and compared with the number of user jobs running as a function of time over the same period:
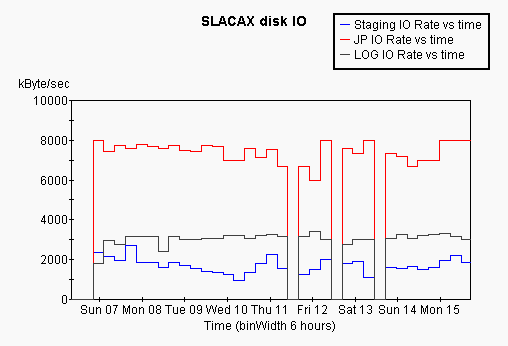
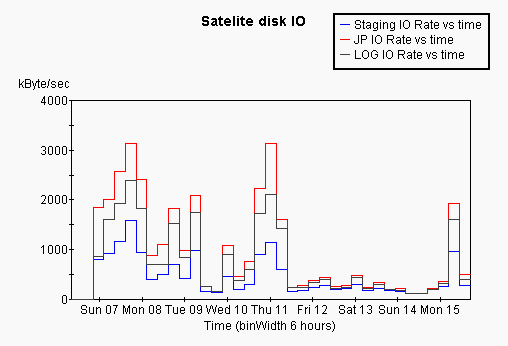
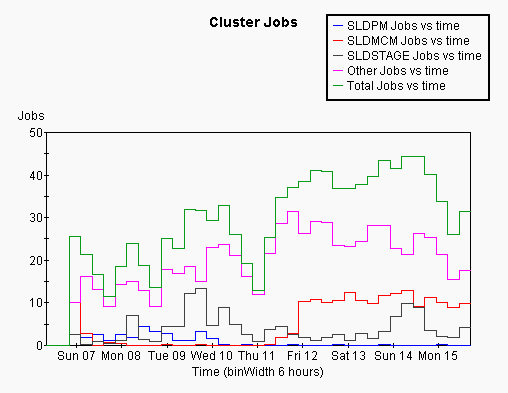
A number of thinsg can be seen from this plot. On SLACAX the disk IO rate is relatively independant of time/load, except that the staging disk shows quite a range of performance. On teh satellite nodes the performance varies dramatically over time in particular towards teh end of the week the peformance is very poor, coinciding with a large number of jobs running on the satellite nodes.
One possible explanation for the poor performance of the satellite nodes would be if the network was becoming saturated when there were a lot of jobs running. The measured network badnwidth is shown below:
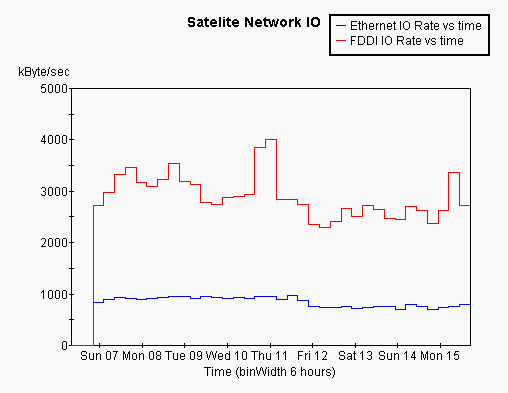
The ethernet IO rate is typically just below 1MB/sec, which is what would be expected from a 10Mbit/sec ethernet, while the FDDI seems to only give 3-4MB/sec, which would seem to be lower than should be expected from a 100Mbit/sec network. Bother ethernet and FDDI show some variation with load, although apparently not enough to explain the shift seen in IO rate. Also the total network bandwidth seems to be well above the IO performance seen on the satellite nodes.
Finally since the test jobs sometimes ran on SLACAX, they sometimes tested the network bandwidth for SLACAX talking to itself. While it is unclear to me exactly what this measures, the variation with time seems bizarre:
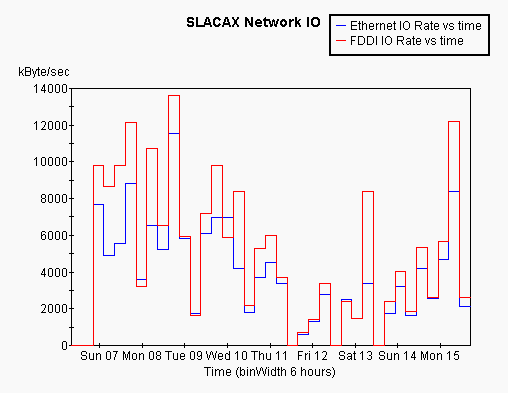
Tony Johnson
15th June 1998